大模型技术概览:从原理到应用
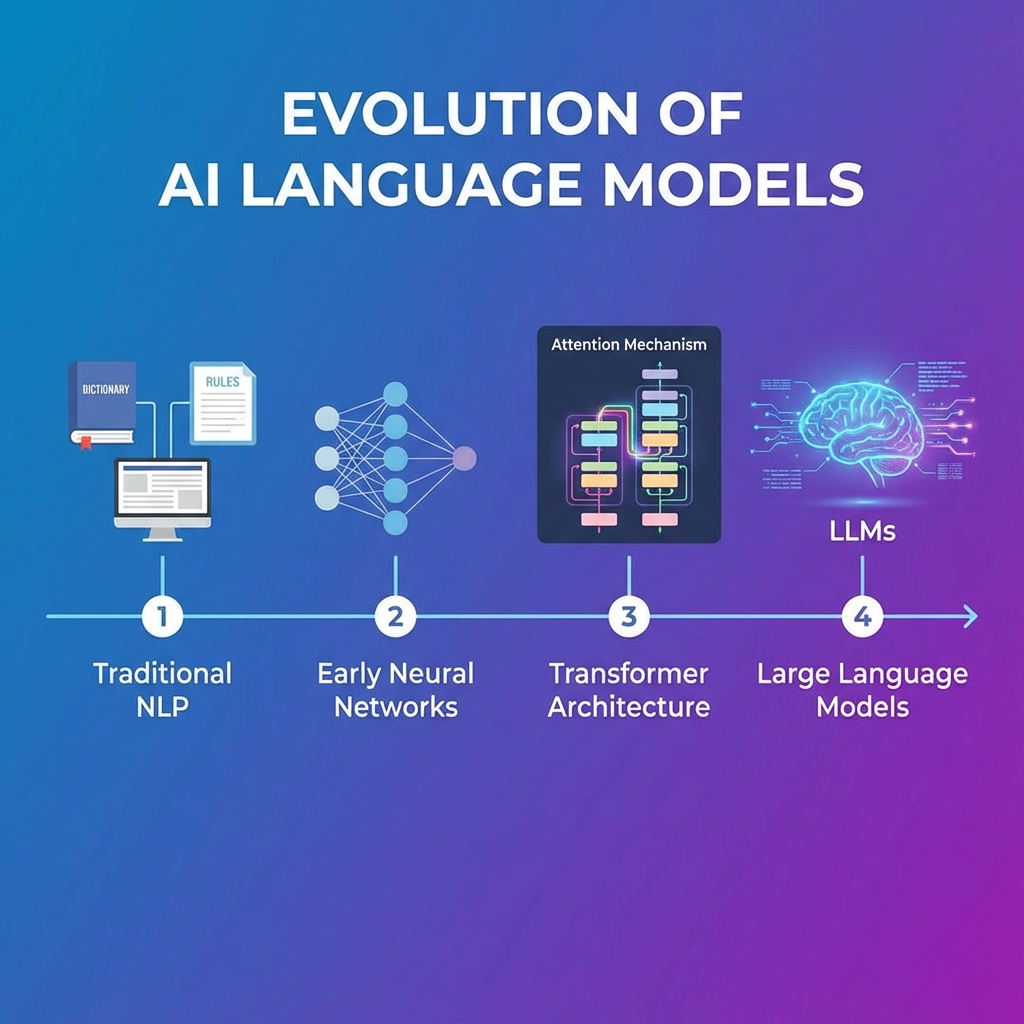
1. 什么是大语言模型(LLM)?
大语言模型是基于 深度学习,在海量文本数据上进行 自监督预训练 的模型,能够 理解、生成、推理 人类语言。它们的核心特征是 参数规模巨大(数十亿到上万亿)和 数据规模庞大(TB 级别文本)。
2. 核心技术栈
| 技术 | 作用 | 示例代码 |
|---|---|---|
| Transformer | 通过自注意力捕获长程依赖 | torch.nn.Transformer |
| Tokenization | 文本 → 数字序列 | from transformers import AutoTokenizer |
| 预训练 & 微调 | 通用能力 → 专业任务 | model.fit(...) |
| Prompt Engineering | 引导模型输出 | "请用中文解释以下概念:" + text |
3. 常见应用场景
- 对话机器人(ChatGPT、Claude)
- 代码生成(GitHub Copilot)
- 检索增强生成(RAG)
- 智能体(Agent):工具调用、任务规划
4. 入门代码示例:使用 HuggingFace transformers 生成文本
_10from transformers import pipeline_10_10# 加载一个小型的开源模型(速度快,适合演示)_10generator = pipeline("text-generation", model="gpt2")_10_10prompt = "介绍一下什么是大语言模型(LLM)"_10result = generator(prompt, max_new_tokens=100, do_sample=True, temperature=0.7)_10print(result[0]["generated_text"]) # 打印生成的文本
提示:在本地运行前请先
pip install transformers torch。
5. 小结
大模型技术已经从 概念探索 进入 落地实用 阶段。掌握 Transformer、Prompt 与 RAG 等核心概念,配合实践代码,即可快速上手并构建自己的 AI 应用。 帮我把版权信息放到网站底部,网页高度低于屏幕时候调大页面高度
帮我把版权信息放到网站底部,网页高度低于屏幕时候调大页面高度
Discussion4
Michael Chang·20h ago
The section on Context Windows vs RAG was really illuminating. I've been debating which approach to take for our internal knowledge base.
Do you think the 1M+ context windows in newer models will eventually make RAG obsolete?
Sarah ChenAuthor·18h ago
Great question, Michael! I don't think RAG is going away anytime soon. Even with huge context windows, RAG offers better latency, cost-efficiency, and most importantly - the ability to cite sources explicitly.
Priya Patel·Dec 22, 2025
I finally understand how Positional Encodings work! The visual analogy with the clock hands was brilliant. 👏
DevOps Ninja·Dec 22, 2025
Any chance you could cover Quantization (GGUF/GPTQ) in a future post? trying to run these locally on my MacBook and it's a bit of a jungle out there.